准备数据集
labelImg 数据标注工具
模型结构 如下图:
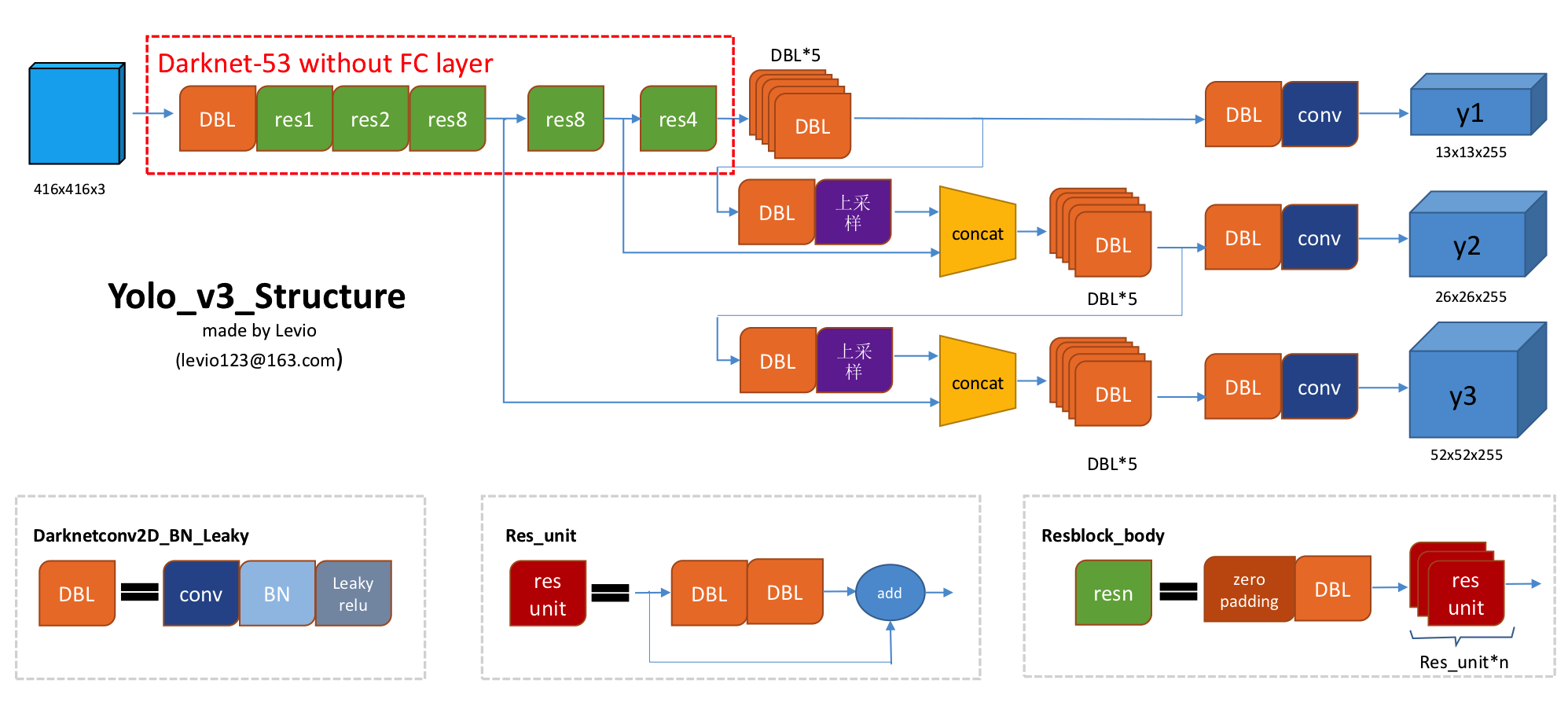 网络输入 416x416 经过一系列卷积层之后分成了三个分支,最终得到三个输出:[13,13,c],[26,26,c],[52,52,c] c是通道数
网络输入 416x416 经过一系列卷积层之后分成了三个分支,最终得到三个输出:[13,13,c],[26,26,c],[52,52,c] c是通道数
feature map 越大,感受野越小,适合预测小目标,
[13,13] feature map适合预测大目标
数据 target转换
同等变换,[512,512,3] => [13,13,5]
因为网络输出是 [13,13,255] [26,26,255] [52,52,255]
这里的255是:3*(5+80) 每一个网格预测3个bbox,每个box有(x,y,w,h,iou,classes)
所以要将y_true也进行转换 [13,13,3,6] =>[13,13,3,(x,y,w,h,iou,class)]
意思是 512x512的图片上的真是框 映射到13x13的 feature map上,缩放32倍
每个图片上 最多有 gtbox_max个框,每个box 有5个值[x,y,w,h,confidence]
因为网络输出是中心点坐标,所以x,y得转换成中心点坐标
图片转换成网络输入大小
x = [h,w,3] => [416,416,3]
label转换成网络输出 yolov3有9个anchors 网络输出有三个分支:
[boxes,(x,y,x1,y1,class)] =>[13,13,3,(x,y,w,h,confidence,class))] # x,y是中心点坐标
[boxes,5] =>[26,26,3,6]
[boxes,5] =>[52,52,3,6]
y